









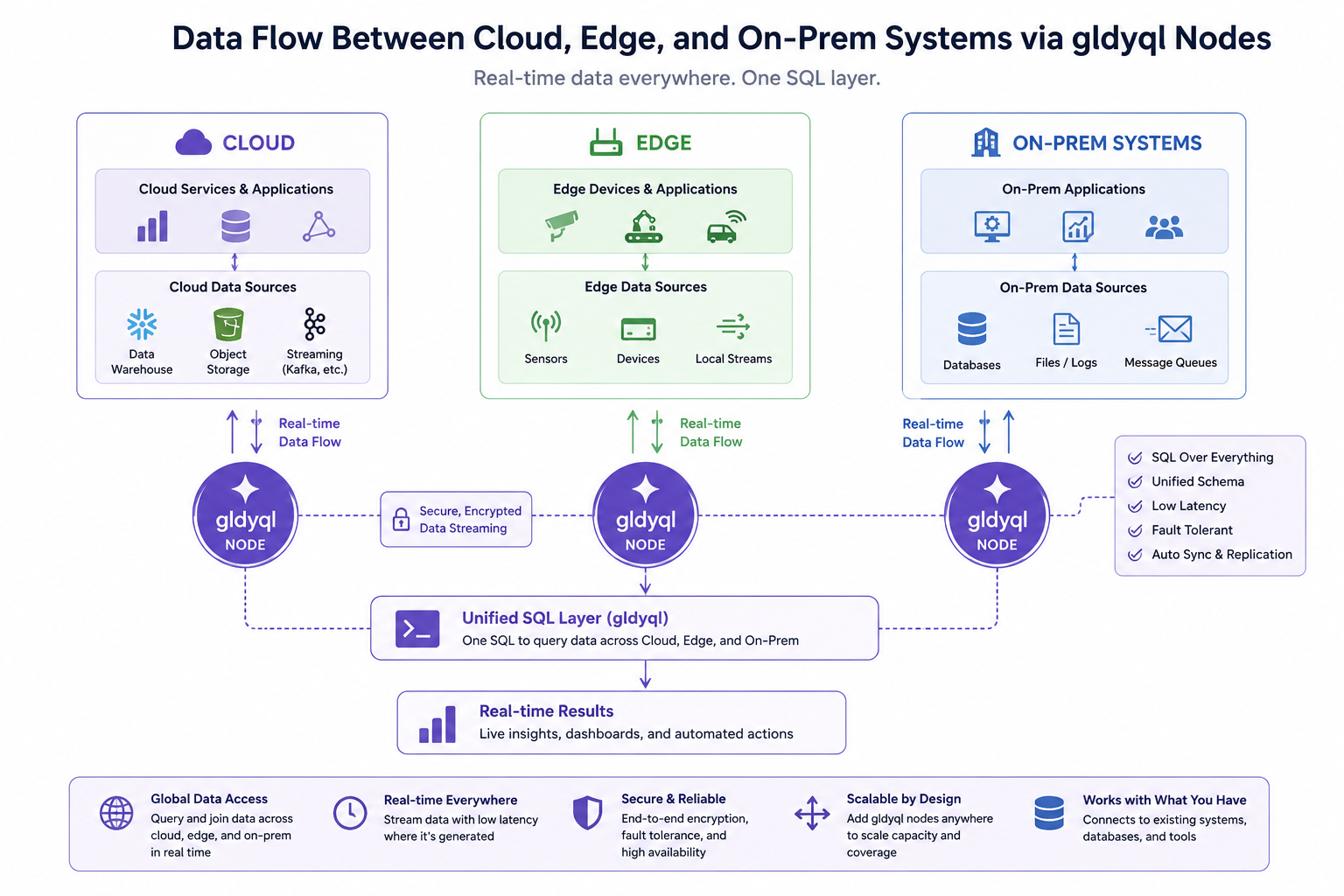
gldyql (pronounced “glid-i-kul”) is an emerging open‑source framework designed for real‑time data synchronization across distributed systems. Its core purpose is to eliminate latency mismatches between cloud databases, edge devices, and legacy on‑premise infrastructure. By using a lightweight event‑streaming protocol, gldyql ensures that every connected node sees the same consistent dataset within milliseconds.
Whether you manage a small API backend or a global IoT network, gldyql reduces the complexity of building reliable data pipelines. In this guide, you’ll learn how it works, why it matters, and how to integrate it into your stack today.
The Connection to Innovation
Modern digital trends edge computing, real‑time analytics, and decentralized architectures all depend on fast, conflict‑free data replication. Traditional batch ETL (Extract, Transform, Load) tools cannot keep up with the sub‑second demands of AI inference or live dashboards. gldyql fills this gap by combining:
-
Stream‑first design – Data moves as events, not batches.
-
Automatic conflict resolution – Last‑write‑wins and merge strategies are built‑in.
-
Low‑code configuration – YAML schemas replace thousands of lines of glue code.
Pro Tip: gldyql works particularly well with Kafka and Redis. Use the built‑in Kafka sink connector to stream database changes directly into your analytics warehouse without custom consumers.
Core Technical Pillars
Data Management Aspects
gldyql treats all information as immutable event streams. Each operation (insert, update, delete) becomes a timestamped log entry. This approach gives you:
-
Complete audit trails – Every change is replayable.
-
Idempotent processing – Replaying the same stream produces the same final state.
-
Schema evolution support – Add new fields without breaking existing consumers.
Internally, gldyql uses a hybrid logical clock to order events even when network partitions occur. You never lose writes, and you never see stale reads.
Security & Reliability
Security is built into the transport layer and the access model:
-
Mutual TLS (mTLS) – Every node authenticates using certificates; no plain‑text fallback.
-
Fine‑grained RBAC – Control read/write permissions per stream or per field.
-
Automatic retry with exponential backoff – Handles transient network failures without manual intervention.
For reliability, gldyql offers stateful checkpointing. If a consumer crashes, it resumes exactly where it left off—no data loss, no duplicates.
Safety Warning: Never expose the gldyql control port (default 9090) to the public internet. Always place it behind a VPN or a reverse proxy with strict firewall rules. The control API can reset stream offsets, which might skip critical transactions if misused.
Practical Applications
Personal Use Cases
Individuals can use gldyql to synchronize data across personal devices:
-
Keep a private note‑taking app in sync between a laptop, phone, and home server.
-
Build a local RSS reader that pulls feeds once and shares read/unread status across all your gadgets.
-
Automate photo backups – New images on your phone instantly appear on your NAS without cloud uploads.
Team & Business Applications
Startups and enterprises gain three major advantages:
| Use Case | Benefit |
|---|---|
| Multi‑region product catalogs | Update a price in EU → reflects in US and Asia within 200ms. |
| Real‑time support dashboards | Every ticket status change is pushed to all agents immediately. |
| Cross‑database sync (PostgreSQL ↔ MongoDB) | Maintain both SQL and NoSQL versions without double‑writes. |
One logistics company reduced data‑sync errors by 94% after switching from a custom script to gldyql’s CDC (Change Data Capture) pipelines.
Educational Use
Teachers and students can use gldyql to learn modern data engineering concepts:
-
Simulate a stock ticker – Produce fake price events and consume them with a live chart in Python.
-
Teach event‑sourcing architecture – Compare state‑based vs. event‑based systems side by side.
-
Build a collaborative whiteboard – See real‑time cursor movements without WebSocket boilerplate.
The official gldyql Academy (free) offers interactive labs that run entirely in a browser.
Critical Analysis
Benefits
-
Low latency – End‑to‑end delivery under 100ms for typical 5‑node clusters.
-
Operational simplicity – One binary, no external coordination service (no ZooKeeper, no etcd).
-
Language‑agnostic clients – Officially supported SDKs for Go, Python, Node.js, and Rust.
-
Built‑in dead‑letter queues – Failed events go to a separate stream instead of blocking the pipeline.
Challenges
-
Learning curve for event‑thinking – Developers used to REST APIs often initially struggle with stream semantics.
-
No native Windows binary – Requires WSL or Docker on Windows hosts.
-
Limited third‑party connectors – While Kafka and RabbitMQ are supported, you won’t find Salesforce or SAP adapters out of the box.
-
Storage overhead – Immutable logs can grow quickly; you need to configure retention policies (e.g., keep 7 days of history).
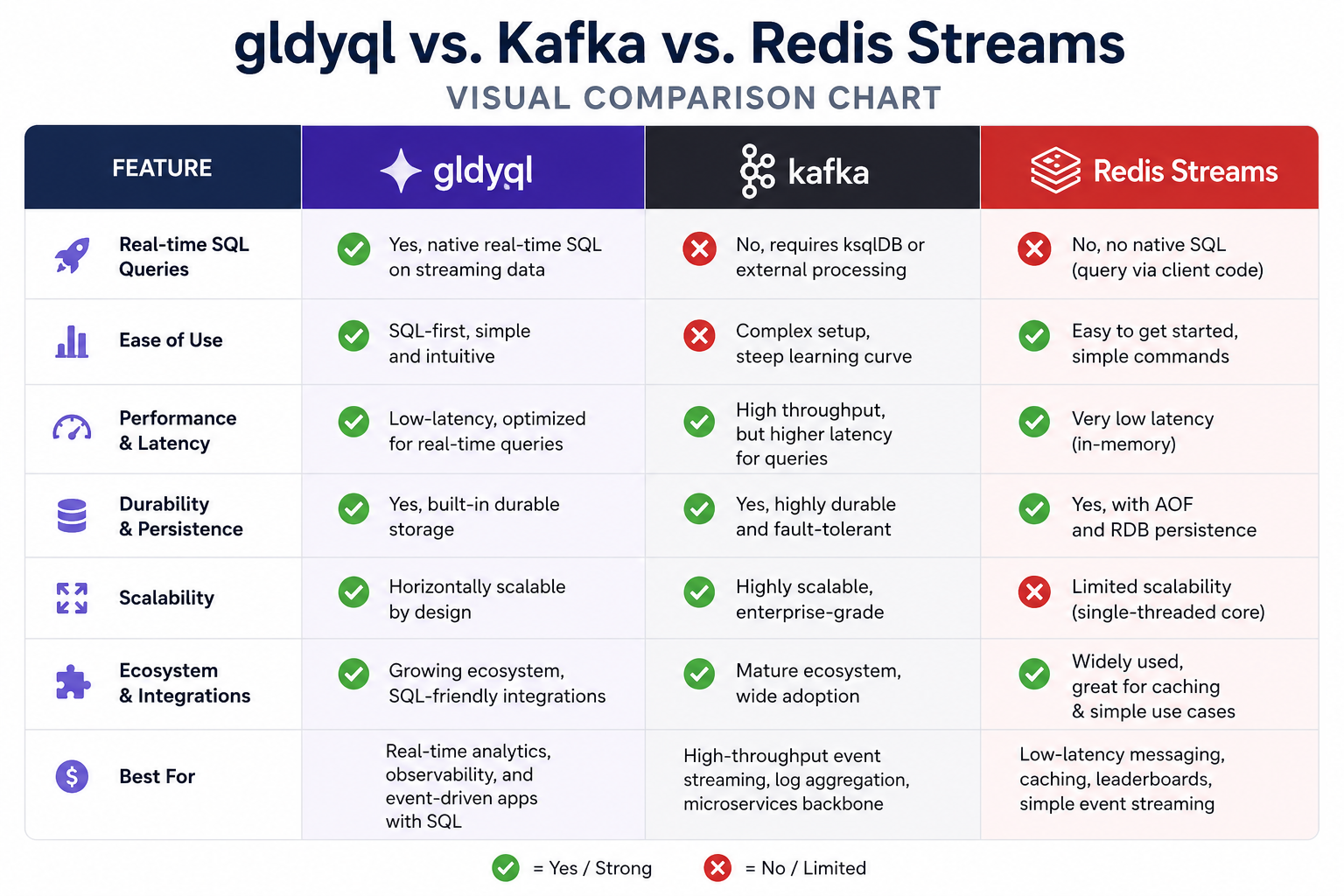
Comparative Analysis
| Feature | gldyql | Apache Kafka | Redis Streams | NATS JetStream |
|---|---|---|---|---|
| Deployment complexity | Low (single binary) | High (needs ZooKeeper) | Medium (depends on Redis) | Low |
| Exactly‑once semantics | Yes | Yes (since 0.11) | No (at‑least‑once) | Yes |
| Built‑in conflict resolution | Yes (last‑write‑wins) | No | No | No |
| Edge‑native (low RAM) | Yes (~50MB) | No (~1GB+ typical) | Yes | Yes |
| SQL query on streams | No (use separate tool) | Yes (ksqlDB) | No | No |
Choose gldyql when you need simple, reliable sync across many small nodes. Choose Kafka for massive throughput (millions of events/sec) with a dedicated team to manage it. Chooses Redis Streams if you already have Redis and don’t require strong ordering guarantees.
Implementation & Future
The Roadmap
Three trends will shape gldyql’s evolution over the next 18 months:
-
WebAssembly (Wasm) filters – Run custom transformations directly inside the stream without separate microservices.
-
Native MQTT bridge – Seamless integration with industrial IoT sensors.
-
Managed cloud service – A fully hosted version with automatic scaling and pay‑per‑event pricing.
The core team also plans to add active‑active geo‑replication by Q4 2026, allowing two independent clusters to sync bi‑directionally without loops.
Practical Integration Guide
Follow these seven steps to integrate gldyql into your daily work or production environment:
-
Download the binary from the official GitHub releases page (Linux/macOS only; use Docker for Windows).
-
Run a single node for testing:
./gldyql server --config minimal.yaml -
Create a stream using the CLI:
./gldyql stream create orders --retention 72h -
Produce a test event:
echo '{"orderId": 123}' | ./gldyql produce orders -
Consume the event in Python:
from gldyql import Consumer c = Consumer(stream="orders") for msg in c: print(msg.value)
-
Add a second node for redundancy:
./gldyql server --join 192.168.1.10:9090 -
Set up automatic backups – Use the
snapshotcommand to dump stream offsets to S3 every hour.
Pro Tip: For production, always run at least three nodes. Configure
quorum: 2in your YAML to tolerate one node failure without losing write availability.
Tools & Resources
| Tool | Purpose |
|---|---|
| gldyql‑cli | Manage streams, check health, replay events |
| Prometheus exporter | Built‑in metrics endpoint (/metrics) |
| gldyql‑ui | Open‑source web dashboard (GitHub) |
| VSCode extension | Syntax highlighting for stream definitions |
| Terraform provider | Provision gldyql clusters as infrastructure‑as‑code |
Start with the official playground (play.gldyql.io) – no installation required, runs in your browser.
Conclusion
gldyql solves the painful problem of keeping data consistent across fast‑moving, distributed systems. Its event‑streaming model, combined with low operational overhead, makes it ideal for edge deployments, real‑time dashboards, and multi‑database sync. While it lacks some enterprise connectors and native Windows support, its simplicity and built‑in reliability often outweigh those limitations.
Ready to try it? Run curl -fsSL https://get.gldyql.io | sh on a Linux or macOS machine – you’ll have your first stream running in under two minutes.
Frequently Asked Questions
1. Is gldyql free for commercial use?
Yes. gldyql is licensed under Apache 2.0. You can use it in any product, paid or free, without royalties.
2. Can gldyql replace a message queue like RabbitMQ?
Partially. gldyql offers at‑least‑once and exactly‑once delivery, but RabbitMQ has richer routing (exchanges, bindings). Use gldyql when you need persistent event sourcing; use RabbitMQ for transient work queues.
3. What happens if a gldyql node loses its disk?
The node will re‑join the cluster and catch up from other nodes. However, if you lose the entire cluster (all disks), you must restore from a snapshot backup. Always schedule automatic snapshots.
4. Does gldyql encrypt data at rest?
Not by default, but you can enable LUKS (Linux) or BitLocker (Windows via WSL) on the underlying disk. The project roadmap includes native AES‑256 encryption for stream files.
5. How does gldyql compare to CDC tools like Debezium?
Debezium captures changes from databases (MySQL, Postgres) and pushes to Kafka. gldyql is a general‑purpose stream store. You can run Debezium → Kafka → gldyql to get both database CDC and lightweight consumption at the edge.